In our last release, I announced that JS++ core is down to nine (9) minor bugs after 3.5 years of engineering.
Here is the data for our lines of code:
| Language | files | blank | comment | code |
|---|---|---|---|---|
| C++ | 511 | 28,449 | 9,478 | 120,915 |
| C/C++ Header | 578 | 25,427 | 30,498 | 110,327 |
| C | 1 | 11,333 | 18,124 | 57,047 |
| JS++ | 21,118 | |||
| Python | 35 | 862 | 401 | 2,817 |
| Data collected May 6, 2019 9:50AM PDT | ||||
In total, JS++ core consists of over 400,000 lines of code constructed over 3.5 years of engineering. This article discusses the software engineering methods behind JS++ to deliver high-quality and reliable software. Specifically, this article may be of particular interest because we will focus on a software engineering method for real-world compiler engineering; compilers sit at the foundation (bottom) of a technology stack, and a single bug with the compiler can make-or-break a software project. Thus, when high reliability and high correctness are needed in software, what can we do?
Software Development Methodology
It might be expected that JS++ would use a predictive model for software development, such as a variation of waterfall like the sashimi or incremental waterfall models, for the design of programming languages and engineering of compilers. After years of compiler releases, we have made almost no breaking changes. In contrast, our competitors at Microsoft TypeScript make breaking changes on almost every version release and dedicate an entire page to documenting breaking changes. Thus, clearly, the evidence suggests JS++ must have thought through every intimate detail with a Big Design Upfront (BDUF)?
We apply a holistic approach which accounts for resources, market forces, risk, product design, and software development. We will examine these aspects in further detail.
Resources
Resources include staffing, budget, and time. When considering staffing, we consider full-time staff, part-time staff, contractors, and consultants.
JS++ ships with 15 third-party development environment and text editor integrations, including plugins for Visual Studio Code, vim, and emacs. In addition, we have also shipped editor integrations for less popular editors that our competitors do not support officially, including nano and UltraEdit.
The development of third-party editor integrations is handled by external contractors. The employment of external contractors carries risk: you might not be able to find the right contractor, you might not be able to find any contractor (with the requisite skills and experience for your budget), or the contractor might not be able to complete the project.
In addition, we occasionally employ outside consultants specializing in programming language theory or compiler construction. We employed a core contributor from the gcc team to incorporate unlimited lookahead, which enables parsing more expressive grammars, into the JS++ parser based on a paper on LL(*) parsing by Parr and Fisher.1 This forms the basis for more powerful disambiguation facilities within the JS++ parser.
Consultants typically charge on an hourly basis. If a budget is fixed, the possibility exists that a consultant’s invoice will exceed the budget allocated. If management refuses to exceed a fixed, pre-planned budget, the risk exists that the team will need to move forward with incomplete information or contributions. Furthermore, if budgets are exceeded based on ad hoc decisions in response to changing requirements, financial risk will be introduced into the development process.
Given the risk profile, it should be clear that predictive models for software development will not suffice for our situation.
Market Forces
In predictive models of software engineering, the assumption needs to be made that the project is isolated or insulated from external market forces. For business software, this is almost never the case. As an example, if the sponsoring company goes bankrupt, the software project cannot continue. In contrast, an open source MD5 library written as an exercise or experiment is largely isolated from market forces.
We use Porter’s Five Forces Framework to analyze market forces, which allows us to assess competition and disruption to determine the viability of a software project. This needs to be understood as a high-level business analysis. For example, we have the technical capability to make breakthroughs, such as the JS++ “Feather” proof of concept:
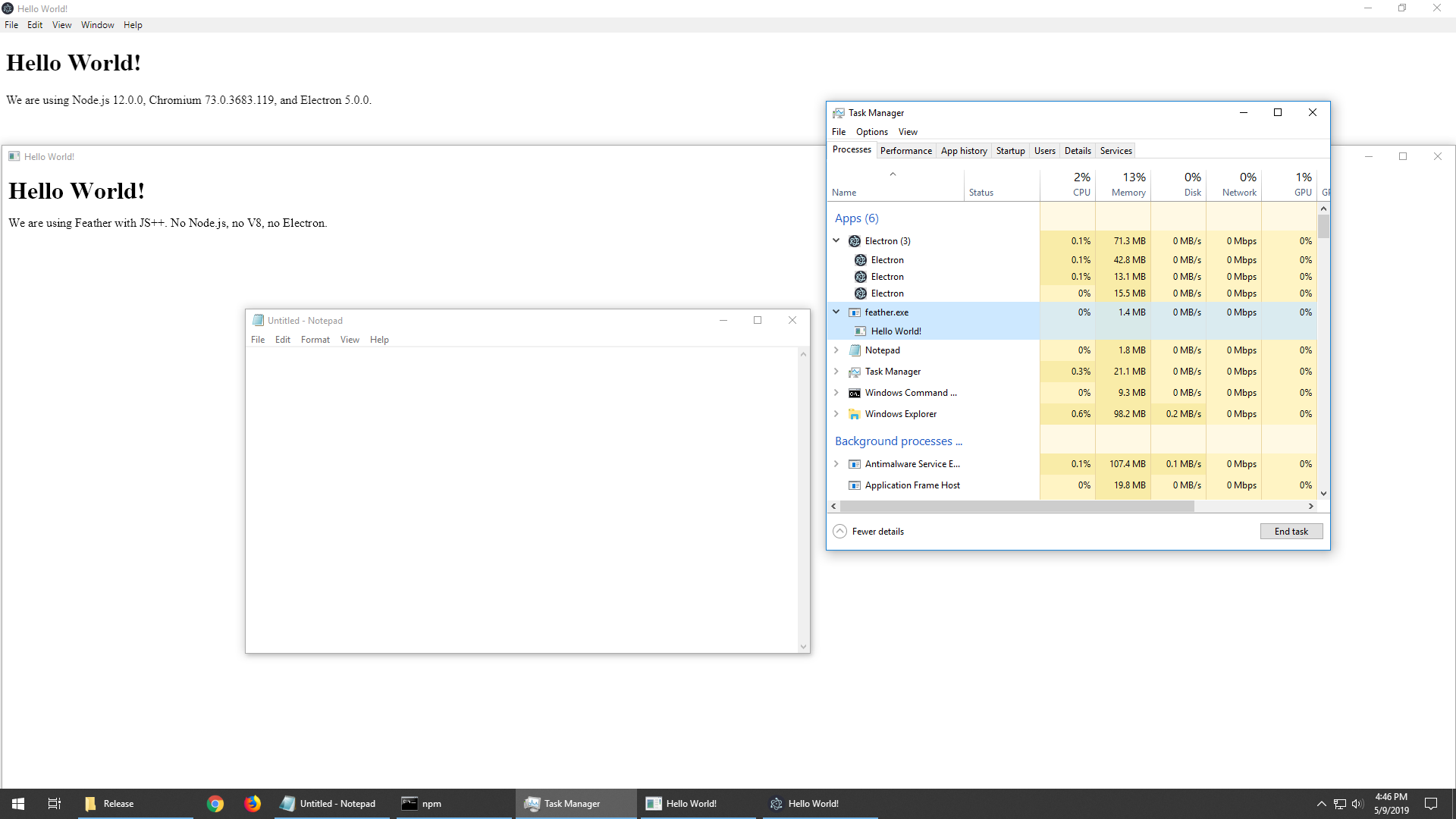
Here, the JS++ team demonstrates exceptional technical capability. We optimize memory by 50x compared to Electron, with further optimization opportunities at scale. In addition, as a demonstration of technical competency, we show that an application with custom font and pixel rendering can be more memory-efficient on startup than Notepad, which uses a standard Win32 edit control: 1.4mb (Feather) vs 1.8mb (Notepad) memory usage.
The efficiency gap is similar on Linux. Electron consumes 101mb memory, while Feather only consumes 2.4mb memory (shown here with 9.8mb memory usage but has since been optimized dramatically).
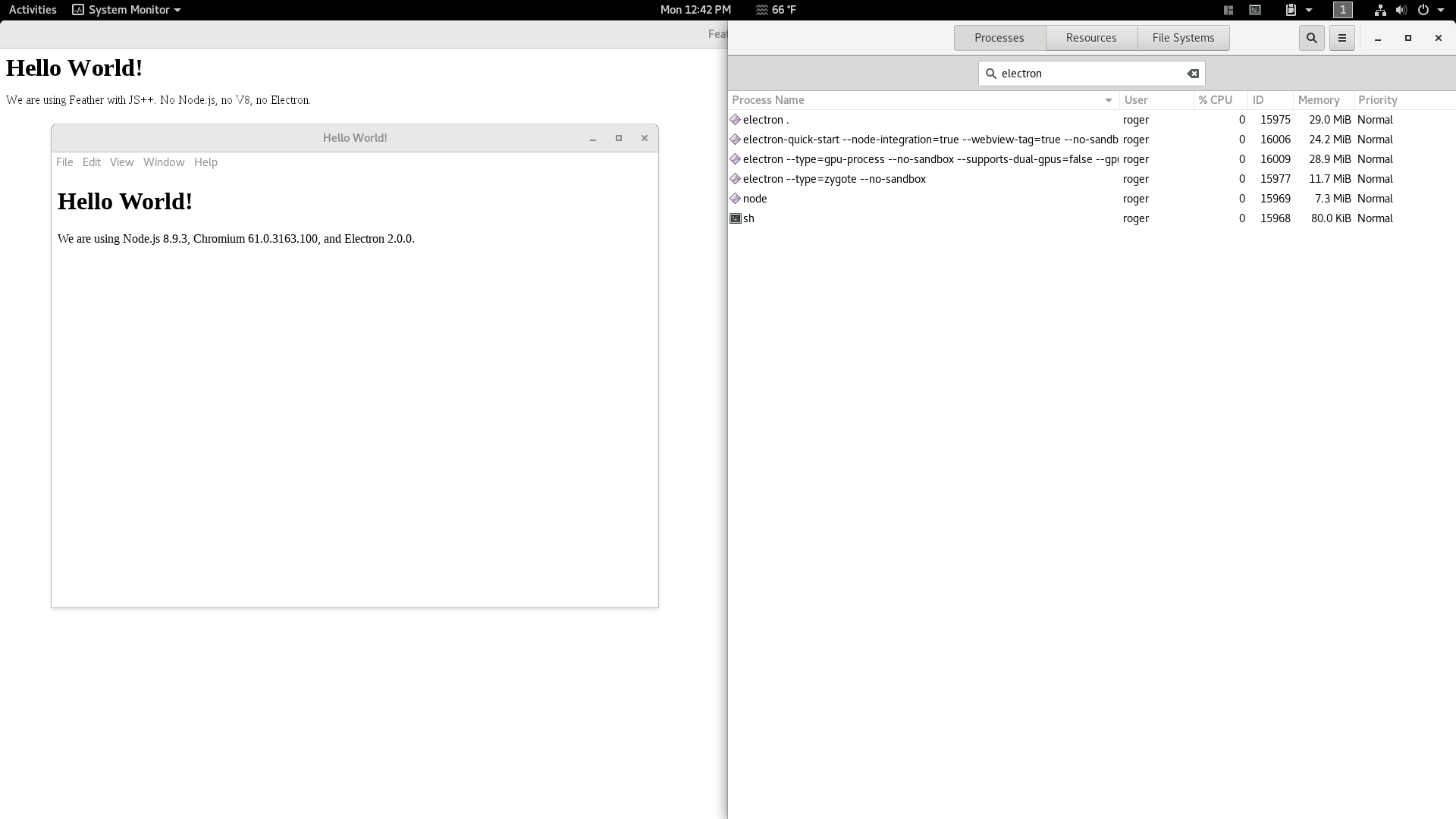
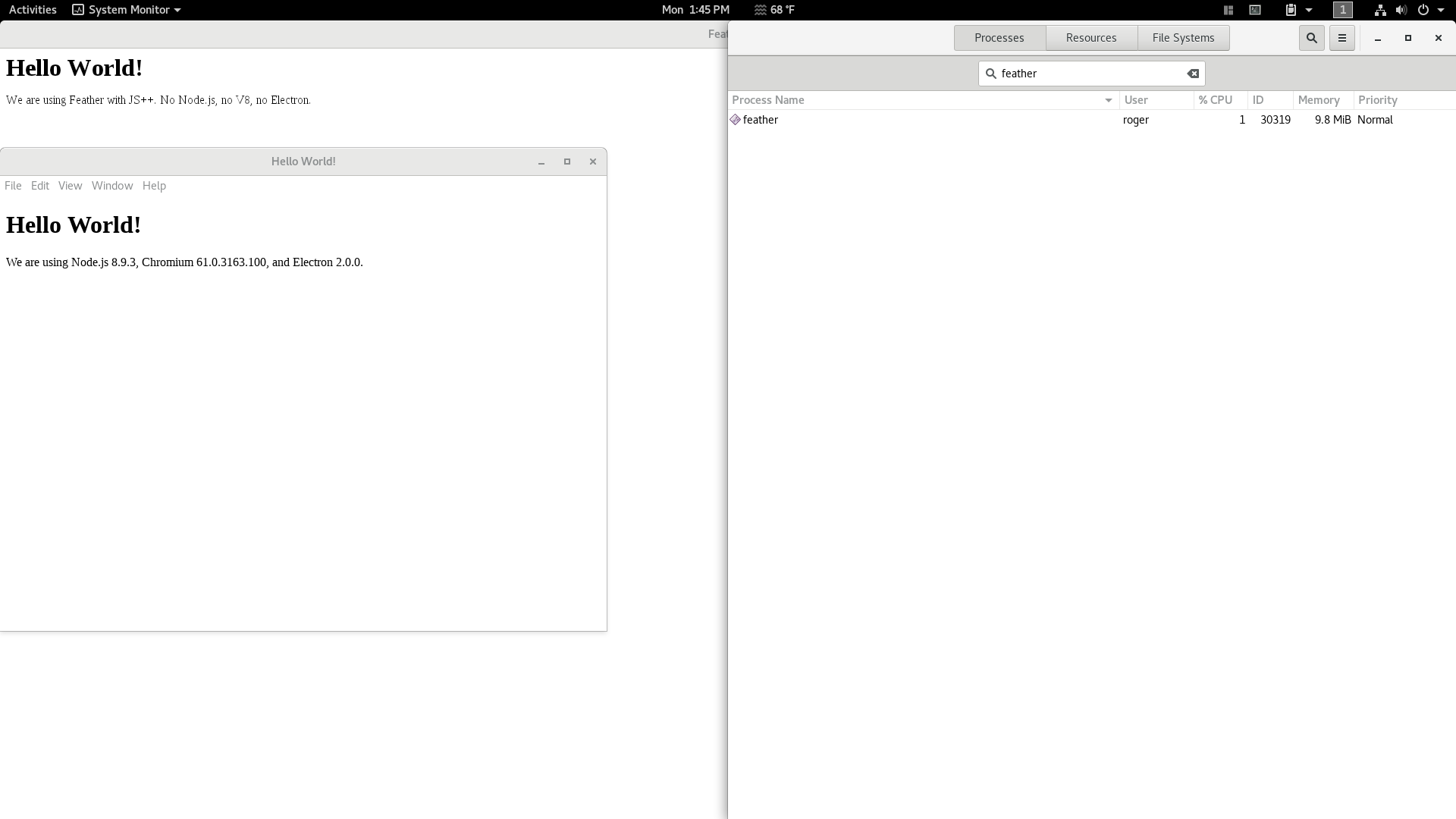
Side note: Theoretically, it is impossible to achieve the efficiency characteristics of JS++ Feather with plain JavaScript. Principally, the problem is JavaScript itself. However, this risks digression from the topic at hand: software engineering methods. Performance and efficiency are closely linked with language design. The JS++ blog provides plenty of in-depth technical discussion ranging from language design to compiler engineering. See those and connect the dots.
If we apply the Five Forces model, we understand that this is an undesirable direction for a team with limited resources. The threat of new entrants, specifically new “good enough” entrants, is high. The threat of substitutes is also high; Electron and competing alternatives all currently exist for free.
UI innovation is also moving fast. I’ve seen the industry shift from DHTML (in the 1990s) to jQuery to React/Angular/MVC. When the industry is moving faster than your development output, you risk facing disruption before reaching the market.
When we analyze the “threat of change,” we realize that the requirements are subject to change. Once again, this rules out predictive models such as waterfall. By analyzing a project holistically, we eliminate waste—which will be covered in more detail later.
Risk
When we perform a risk assessment, we begin by identifying different types of risk that the project may get exposed to: project risk, market risk, and financial risk. The market and financial risks have been described. However, project risk deserves special attention as it extends into programming best practices developers will be familiar with.
We manage project risk by identifying complexity and repeatedly simplifying. Most of our risk management attention at the development stage of the SDLC is focused on mitigating or eliminating project failure risk through simplification of the code and class structures by way of refactoring: dependency complexity, class fragmentation, bloated classes, DRY, splitting methods, and—especially—naming.
At a basic level, this is accomplished with a test-code-refactor cycle, which we will cover in more detail later. Evidence of our dedication to reducing system complexity can be seen in one of my final thoughts when we released existent types:
Our first priority is to manage engineering complexity. We have to refactor our tests, and none of this will show up for you, the user. As I write this, I don’t know what to expect. Existent types can bring demand for JS++, but we don’t have the resources to manage this demand. Instead, we have to stay disciplined in sticking to our own internal schedules to ensure the long-term success of JS++. We listen to user input, but we don’t (and can’t) follow hype and trends. JS++ over the next 25 years will be more important than JS++ over the next 25 days. I point to Haskell as an example: it’s a programming language that is well thought-out and has persisted for 29 years.
We have users that have followed us for years, and we thank all of them for giving us the motivation to persist. If you’re willing to be patient and watch JS++ evolve, I urge you to join our email list. The sign-up form for our email list can be found by scrolling to the bottom of this page.
When we refactor and address technical debt, it’s also important to point out that we consider nonfunctional requirements, such as performance, in our development process. Evidence of this came in the 0.8.10 release, when we improved our compile times, despite public testimonials remarking that the JS++ compiler already had “instant” compile times. (Nothing is truly “instant,” but our compile times remain below the threshold for average human reaction times: 250ms. In contrast, it takes TypeScript over 1 second to compile “Hello World”—a duration we have yet to lag to even on real-world projects of reasonable complexity.)
Since software performance characteristics and regressions cannot be predicted in advance, the waterfall model is once again not ideal. Furthermore, incremental models for software development, such as incremental waterfall, are also unsuitable for managing the JS++ risk exposure. As evidenced in some releases, we aren’t always releasing new features with each release; thus, our approach clearly encompasses iterative elements rather than purely incremental.
Product Design
When we consider product design, we also consider innovation. Innovation, especially outside-the-box ideas, are unpredictable and follow a non-linear path, as observed by Thomas Kuhn.2 When we invented existent types to prevent out-of-bounds errors, the requirements needed to change to support the invention.
It may come as a surprise, but the requirements for a new language design can sometimes be fuzzy. It was not initially clear how JS++ should handle out-of-bounds errors. The following screenshot shows we were genuinely confused one year before inventing existent types:
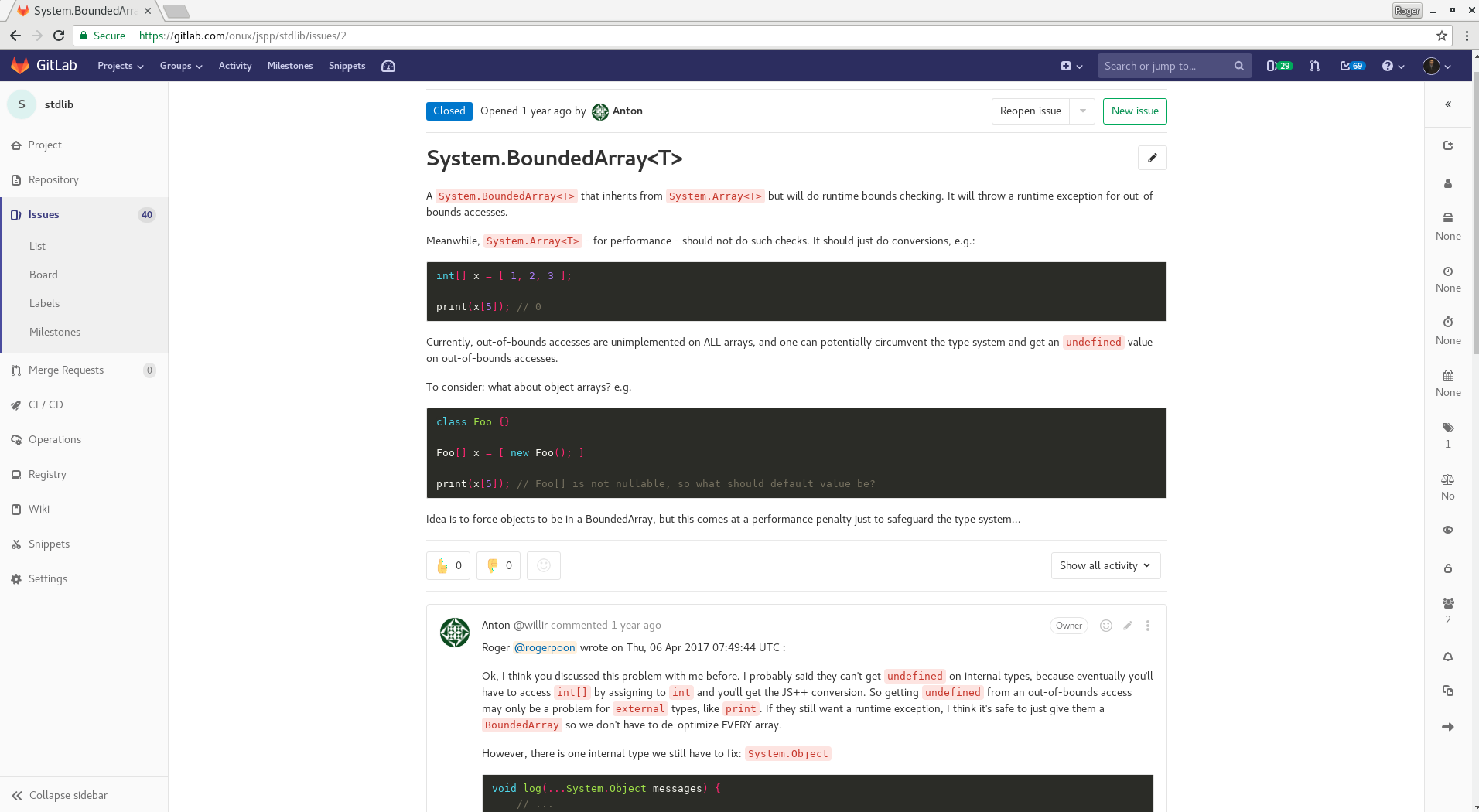
In the context of the traditional waterfall model, which uses a sequential development process, the entire project would need to be delayed until this one design consideration was resolved. In variations of waterfall, such as the sashimi waterfall, this problem can be addressed to a limited extent, sometimes at the expense of increased risk exposure.
Additionally, issues with the language design may only surface later in the SDLC, such as during the development or testing phases. As an example, extensive testing may uncover “corner cases.” Language design is inherently fraught with corner cases (look at C++). When a system may contain many corner cases, the waterfall model is not ideal as all corner cases would need to be known and addressed upfront.
Software Development
We look at software development holistically. For example, one of our first considerations was: how easy would it be to hire developers? Specifically, which programmers are going to be strong in compiler engineering? Compilers are traditionally written in C++. (I’m personally not a fan of self-hosting compilers, as, by definition, they introduce a circular dependency.)
Thus, given numerous options, such as Haskell, Rust, C, and others, we chose C++. In retrospect, for all its warts, I’m still glad we chose C++. It means our engineers and contractors all share a common language. C++ is also the de facto industry standard for compiler engineering, used by gcc, clang/LLVM, the original C# compiler, and so on.
Lean Software Development (LSD)
Deriving from the Toyota Production System (TPS) and “lean” manufacturing, Lean Software Development (LSD) focuses on waste, learning, deciding as late as possible, delivering as quickly as possible, empowering team members, building in integrity, and seeing the whole. LSD is the software engineering method used by the JS++ project. Beyond software engineering, we try to stay lean at an organizational level, and we apply Lean Startup practices at a company level.3
Waste
Eliminating waste is the primary reason we use the LSD model of software development. “Waste” in lean methods is defined as everything not adding value to the customer. The Japanese use the term muda (無駄), meaning “futility; uselessness; wastefulness.” Practically, “waste” appears in software development as waiting, task switching, work that is only partially completed, extra features, and—especially—building the wrong feature.
Building the wrong feature (or “thing”) is probably the most egregious. Peter Drucker, regarded as the founder of modern management thinking (and coiner of “knowledge worker”), warned that nothing is more wasteful than brilliantly executing the wrong tasks. Hiring brilliant engineers to develop the wrong features that the customer doesn’t want wastes both time and money. For a smaller organization with limited resources, eliminating waste was, thus, the highest priority.
Using real-world examples from JS++ development, the first example of how we eliminate waste is via prototyping. I refer back to the example of Feather to illustrate this concept. Depending on the complexity of the prototype, we may use a throwaway prototype (for complex prototypes) or evolutionary prototype (for simpler prototypes).
For complex prototypes, we eliminate waste by developing a throwaway prototype to circumvent the demanding activities of design, testing, and integration before we have established the technical feasibility. In the case of Feather, we needed to determine if we could achieve the memory efficiency we thought we could before any other activities could take place. Extensive testing with high test coverage for a throwaway prototype that ends up not working is wasteful.
Another real-world example of eliminating waste in JS++ development is how we isolate code-level risk. We use the GitFlow model, which uses feature branches that will only be merged back into the master branch when the feature has reached a satisfactory level. This method of branching can also be used to isolate risk. For instance, before we discovered the toExternal/fromExternal design pattern, we were baking in syntactic sugar to achieve a similar result. (Our engineering team will know this internally by the ‘ConversionRule’ codename.) During testing, corner cases with the design surfaced, and the feature was less than ideal. The feature was tossed by deleting the branch.
Side note: One of the shortcomings of git is that it does not understand the syntactic or semantic structure of programs; thus, the decision to merge or delete a branch cannot be delayed, which does not conform to lean engineering ideals. Ideally, the decision would have been postponable until the feature experienced build or integration test failures. However, this is a tooling rather than process shortcoming.
Decide as late as possible
If it occurs to you that the design of JS++ suffers from almost no corner cases, you may be surprised this comes as a result of lean methods. Mathematical logic alone is insufficient. When I first presented the JS++ type system, I presented a variety of corner cases that only the JS++ type system addressed; I presented the problems of garbage collection bugs for pre-HTML5 WebSocket real-time streaming, host object behavior legally specified by the ECMAScript specification, incorrect implementations of specifications by browser vendors, and many other corner cases that we were aware of exclusively through decades of experience.
We make decisions as late as possible. By delaying decisions, we give ourselves the opportunity to understand all corner cases. One corner case can invalidate an entire design. For example, the context-sensitive grammar of JS++ contained a corner case that would have required us to change the entire syntax and module importing semantics: disambiguations (at parse time) required cyclic import resolution (which can only occur after parsing). I remarked on this here:
In JS++, the user is not required to specify an import order; the compiler will figure out the order to process the input files by itself; unfortunately, this import order can only be figured out after the input files have been parsed (because JS++ imports based on identifiers and not file paths).
This was almost the straw that broke the camel’s back.
The linked article further describes a similar corner case for handling syntactic ambiguities on the type casting syntax. The clean syntax you take for granted required intense engineering and design effort.
By deciding as late as possible with lean methods, we aren’t forced to make breaking changes on each new release. The team is afforded the safety to think in detail and the freedom to nurture ideas knowing decisions can be delayed.
Learning
An observation: every programming language designer seems to go through a "confused mess" phase after their first successful language effort, but before they went on to bigger things.
— Tim Sweeney (@TimSweeneyEpic) June 25, 2019
It has been observed that sometimes it can take two or three tries to get software right. This is because, even for experienced software engineers, we need a period of learning and discovery to gain accurate understandings of the domain and problem(s).
Revisiting the example of Feather and the use of a throwaway prototype, once the prototype has been thrown away, it gives us the opportunity to use our learnings to more accurately define requirements, more accurately form the high- and low-level designs, and more accurately engineer things right the first time rather than making constant revisions. Accuracy reduces risk and the likelihood of project failure.
Mary Poppendieck, who introduced LSD, might disagree with the notion of “getting it right the first time.” Instead, our interpretation of lean principles is different. We qualify bad decisions and incorrect architecture as waste. For our situation, “getting it right the first time” is the ideal, and this is reflected in how we’ve made almost no breaking changes. Learning supports our ability to make the correct decisions and define the correct architecture.
“Getting it right the first time” is commonly associated with predictive models of software development, and agile organizations typically view it with disdain as a knee-jerk reaction. It typically brings to mind the image of the lone architect or a quarreling committee trying to plan the entire project to the right detail with extensive documentation, but there are techniques—which may involve coding and prototyping—that can help you get increments right the first time. Tailor to your needs.
Deliver as fast as possible prudently
In LSD, development teams are encouraged to deliver as fast as possible to enjoy the benefits of cost savings, risk mitigation, and flexibility in delaying decisions.4 However, this isn’t advisable for programming languages and compilers. Instead, we deliver prudently.
Our users know we don’t deliver as fast as possible. By delivering prudently, we minimize breaking changes. New features are internally used in real-world software development before they pass acceptance testing. In this way, we ensure that new features delivered to users will work immediately upon shipping. Have you noticed we never issue next-day patches to fix yesterday’s deployments? This is because we’ve gradually perfected acceptance testing on real-world code.
Empowering team members
In 1982, General Motors (GM) had a problem: it had to close its Fremont plant. Employees hated management so much they would drink alchohol on the job, were often absent from work, and would actively sabotage vehicles. Two years later, GM and Toyota re-opened the plant as NUMMI through a joint venture. GM wanted to learn lean manufacturing from Toyota, and Toyota wanted to establish its first manufacturing base in North America. 85% of the original work force was re-hired; within two years, the NUMMI plant exceeded the productivity of any GM plant. GM tried to reproduce the management practices for its other plants, but it was largely unsuccessful. It turns out Toyota did not transfer Japanese production practices en masse to NUMMI, but they transferred the philosophy of human respect for the frontline workers to achieve maximum productivity.4
For us, it centers on trust. After the high-level design and architecture have been defined, the developers are free to implement as they see fit. The developers are the experts when it comes to implementations—not the architect, not the product owner, not the customer.
There is no micromanagement. Developers are trusted with delivering on time and on budget. Developers on JS++ core are free to implement using their knowledge and expertise. This can produce pleasant surprises; for example, System.Queue<T> being implemented with a ring buffer instead of linked lists was a developer-level decision. (Admittedly, this “hands-off” management style might not work for contractors; we had an incident where a contractor felt underappreciated. Once again, tailor to your needs.)
Integrity: stop the line
Mr. HAGGERTY: The line could never stop, never stop the line.
Mr. MADRID: You just don’t see the line stop. I saw a guy fall in the pit and they didn’t stop the line.
Mr. LEE: You saw a problem, you stop that line, you are fired.
LANGFITT: The result? Tons of defects. Billy Haggerty saw all kinds of mistakes go right down the line.
…
LANGFITT: There were cars with engines put in backwards, cars without steering wheels or brakes. They fix them later, sometimes doing more damage to the vehicle.5
Prior to its joint venture with Toyota, GM manufacturing had a problem: you were not allowed to stop the line. Instead, in lean manufacturing, if a frontline worker finds a defect, he or she has the power to stop the line and fix the defect.
We operate similarly in applying lean practices to JS++. When code becomes cluttered or undecipherable, we stop the line to make time for refactoring. When performance has noticeably degraded, we stop the line to address performance regressions. When the architecture needs to be changed to better support a new feature, we stop the line and fix the architecture even though its benefits are invisible to the user.
Performance engineering should especially be emphasized. We aim for sub-100ms compile times. For a complex, object-oriented language, this isn’t easy. (In fact, it’s quite hard.) We view performance engineering as a continuous process; whereas, the common industry practice is to address performance as late as possible (which usually means “never”). The extent to which many practicing developers in the industry fail to recognize when and how to optimize code can be summed up in this Twitter retweet reply:
Rules of optimization:
1) Design for performance from day 1
2) Profile often
3) Be vigilant on performance regressions
4) Understand the data
5) Understand the HW
6) Help the compiler
7) Verify your assumptions
8) Performance is everyone's responsibilityhttps://t.co/CwwJffnHGz— Emil Persson (@_Humus_) June 27, 2018
The dismissal of performance engineering is likely inspired by Knuth’s quote, “premature optimization is the root of all evil.” However, many developers may be fundamentally misinterpreting this quote. When your design or architecture considers performance, you are not prematurely optimizing; when you manually inline your functions, manually unroll your loops, and implement critical business logic using inline assembly, you’re prematurely optimizing.
We try our best to design for performance, but we make mistakes. When we make mistakes, we refactor. Specifically, we stop the line and refactor. When we stop the line, no new features are being added, and refactoring is the only activity taking place.
As a demonstration of how seriously we take performance regressions and how quickly we address them, JS++ 0.8.10 highlighted “faster compile times” as its primary benefit. We released the following table for “Hello World”:
| Version | Total Time |
|---|---|
| JS++ 0.8.5 | 96.2ms |
| JS++ 0.8.10 | 72.6ms |
| (Lower is better) | |
First of all, shaving off a few milliseconds will largely be imperceptible to a user—especially for “Hello World.” Secondly, this requires context. We already had public tweets and testimonials claiming our compile times were “instant,” but we still stopped the line to address performance regressions.
Viewing the table in absolute terms fails to view the problem from the perspectives we view them from: technical debt and root cause analysis. We identified performance regressions (via profiling, not guessing) as a consequence of the JS++ Standard Library; it needed to be loaded and processed even for a basic “Hello World” program. Since we expected the Standard Library to continue to expand and evolve, we knew that performance would only continue to degrade going into future iterations. Thus, we needed to stop the line and address the problem.
Finally, if you want quality, you need to have a feel for whether your people are overworked. If they’re tired, they’ll get sloppy. This is a good time to slow down project schedules and ease anxieties. (If you have the authority, assign vacation time.)
Seeing the Whole
Seeing the whole circles back to the beginning of lean thinking: anything not delivering value to the customer is waste. From here, we look at the system as a whole. This extends beyond compiler engineering. What is the user trying to accomplish?
We look beyond technology when we evaluate the whole. For example, it’s easy enough to think that JS++ needs to support MVC, MVP, MVVM, and MV* applications. It’s further obvious that JS++ needs to support Node.js on the backend. These are the obvious problems. However, TypeScript already has this covered. Thus, when we think about delivering value, we perform a competitive and market analysis, and we ask ourselves, “Does it make sense to deliver value here? In what other ways can we deliver value?”
For us, the SDLC begins with seeing the bigger picture: long-term goals, uncovering the “why” before the “what,” and strategy.
The long-term business goals are outside the scope of this article. However, language- and project-level values will be discussed. In no particular order, the fundamental properties of application software that we care about are:
- Speed
- Security
- Reliability
- Scalability
- Robustness
- Maintainability
- Backwards compatibility
- No vendor lock-in
These desirable properties are goals for JS++ that “guide” our design and development process. With high-level goals in mind, it’s also important to understand the “why” before the “what.” As an example, the team was reluctant to refactor abstract syntax tree (AST) annotations used for code generation. However, AST annotations are the “what,” so extensive discussions on the pros, cons, and “how” of refactoring AST annotations misses the bigger picture.
The “why” behind refactoring AST annotations is that the future of programming language performance is heading in the direction of compile-time evaluation. This began in C++11 with constexpr (and even earlier via template metaprogramming). The C++20 committee has been expanding this further via consteval. Compile-time evaluation has been touted as one of the reasons for why C++ can be faster than C. However, there are some weaknesses in the C++ approach:
- C++ compilers use an interpreter for compile-time evaluation
- The C++ language contains many corner cases that prevent compile-time evaluation being applicable generally
- Beyond textbook optimizations, such as constant folding, C++ compilers generally do not evaluate code at compile time unless explicitly asked to do so.
For the first weakness, JS++ can evaluate code by generating intermediate JavaScript code and executing via V8 JIT. Unlike C++, JS++ cannot make unrestricted accesses to memory, the file system, and so on. Vanilla V8 provides a sandboxed environment and fast JIT code execution. Therefore, JS++ programmers can write code quite generally and expect compile-time evaluation and optimization. Since we care so much about fast compile times, refactoring AST annotations and further improving our very fast compile times was motivated by a bigger “why”: the UX and performance of compile-time evaluation.
We want JS++ compile-time evaluation to be able to operate at significant scale. The vision here is that users should be able to write complex, compile-time applications such as parsers and compilers for domain-specific languages (DSLs), custom static analysis passes (e.g. for domain-specific security considerations), etc. (It’s not that these can’t be done via C++; it’s more about the cumulative considerations of C++ compile-time code interpretation, how compile-time C++ code cannot be written with the same intuition as “general code,” how long it takes C++ code to compile, and so on which make JS++ more appealing and pleasant.) Once the type of application reaches a certain level of complexity, JIT compilation (e.g. via V8) becomes further desirable.
For the second weakness, JS++ practices a process of continuous simplification. This has been previously discussed so we’ll avoid going into detail. We simplify the language design until we can simplify no further. This pays dividends down the road when we try to add more to the language.
For the third and final weakness, we want users to get the performance benefits of compile-time evaluation and optimization whenever optimization opportunities present themselves. In order for us to do this, we must continually address performance regressions.
Thus, it’s important to think about the “why” in software engineering because developers can usually get encumbered by discussing and focusing on all the details (the “what” and “how”).
Principles
In addition to Lean Software Development, we have several principles that we abide by that aid design and engineering.
Simplicity
I esteem the engineering credo of William Stout – “Simplicate and add more lightness”. https://t.co/0iZtBya0kS
— John Carmack (@ID_AA_Carmack) September 16, 2017
“Controlling complexity is the essence of computer programming.”
“UNIX is basically a simple operating system, but you have to be a genius to understand its simplicity.”
“Everything should be made as simple as possible, but no simpler.”
I might be overquoting, but this one principle cannot be emphasized enough. The titans of computer programming all agree: simplicity is the key. Simplicity permeates throughout our entire organization and process. It is the motivation for why we avoid “waste” and choose Lean Software Development; it is an ingredient of the compiler’s performance; it is the reason the project continues to live and hasn’t exploded from technical debt.
The process of simplification starts at the very beginning: the language design. We endeavor to design a simple language. Here, we apply Albert Einstein’s thinking: “Everything should be made as simple as possible, but no simpler.” We believe that a language can be too simple, and a language must provide a minimum of necessary abstractions. While we can decompose the minimum set of features to enable a C-like procedural and imperative programming style, we believe object-oriented programming (OOP) is a minimum necessary abstraction. Since object-oriented programming has been proven to work in industries ranging from banking to aerospace, we see it is as a fundamental building block for complex applications.
However, we also believe that complexity should not be built on top of complexity. If you want to build complex applications, the language you build on top of should be as simple as possible. You shouldn’t be wrestling with the language when you build complex applications. In fact, even complex applications built on top of a simple-as-possible programming language should take care to repeatedly simplify.
Simplicity is not for beginners. Neither does simplicity imply less intelligence. Rather, simplicity should be held in the highest esteem; it is the process of managing complexity; one cannot “manage” complexity without first understanding the complexity and all its corner cases. A design which understands and addresses all corner cases while being as simple as possible is very, very hard. (It’s the reason it took JS++ so many years to develop its type system.)
Once we’ve laid the foundation of simplicity in the product requirements, we begin a process of “repeatedly simplifying.” This process occurs in our internal implementation, and it can basically be summed up via the “test-code-refactor” cycle. For us, one of the major goals of refactoring is simplification—from simplifying the logic of individual functions to the high-level architecture and class structure. A project that fails to manage complexity via repeated simplification can fail. This is quietly seen in business applications across a wide range of industries every day: software architects want to restart the project from the beginning, software engineers are scared to touch the code for fear they might break something, teams reject change proposals because the system has become a black box and they’re in denial about not knowing how to implement the change request without breaking something, and so on.
Lastly, the most visible result of simplification was the lead in to this text. We simplify bug classifications. We don’t use a 1-9 scale. We use an even simpler scale: LOW, MED, HIGH. Bugs marked as HIGH must be fixed immediately—as soon as they’re filed. Bugs marked MED should ideally be fixed before the next release, but they can sometimes be delayed to the subsequent release. Bugs marked LOW can be fixed at any time.
Using a very simple issue reporting system enables us to deliver high-quality software with low bug density. Developers are never confused on what they need to fix. HIGH bugs may even entail stopping the line so the bug gets fixed. When this simplicity is combined with other software quality processes such as regression testing and performance profiling, a small team can rapidly deliver complex software with almost no bugs.
Correctness
“It’s done when it’s done.”
This is a line that’s typically associated with the video game industry. However, “it’s done when it’s done” has to be balanced with the risk of the software becoming vaporware. As an example from the video game industry, Duke Nukem Forever was widely regarded as vaporware and it took nearly eight years before a video of the game surfaced after the developers announced it would be released “when it’s done.” Actually, there is a solution to preventing the vaporware problem: process and frequent releases. (Admittedly, frequent releases don’t usually occur in the video game industry. However, the right process can be adapted and applied anywhere.)
JS++ development involves simple, repeatable processes such as test-code-refactor. The “code” phase entails a checklist for implementing all dimensions of a language feature:
- parsing
- semantic analysis and type checking
- code generation
- debugging support
The above constitutes our implementation of a single “unit.” Note that the “unit” will differ depending on application domain. For compilers, it is a single language feature. What’s important is that the “unit” is a repeating pattern that leads to the realized and complete software when you sum up all the units. (It is an additive quality.) It’s important for the “unit” you identify be a repeating pattern because, if it isn’t a repeating pattern, you won’t be able to identify a repeatable process for achieving correctness.
If your organization employs timeboxing, it’s important that the process for building reliable and correct software in your domain has been identified at the planning stage of the SDLC. If you timebox before knowing what constitutes correct software, you risk technical debt. Each time you start on the next iteration of your software without having completed the full process for how you qualify “correctness,” you accrue technical debt for the software’s correctness. This is different from the technical debt for a software’s internal class complexity, nonfunctional requirements, etc.
In complex software, all the correctness corner cases you miss when you skip something might be close to impossible to try and fix later. Corner cases multiply with complexity. Thus, it’s important to identify what constitutes correctness for the smallest unit of a complex software, identify a repeatable process for building and testing this unit to completeness, and to stay disciplined in following the process.
All software development teams make tradeoffs: people come and go, some features need to be prioritized over others, etc. However, not all tradeoffs are created equally. Be careful with technical debt accrued on the software’s correctness.
Add, but not Subtract
This principle was invented by our lead engineer, Anton Rapetov. It ties back in with delaying decisions in Lean Software Development.
The idea is that we can always add features later, but we can never subtract. Thus, when we cannot come to agreement on the design of a language feature or when we cannot resolve all corner cases, we delay.
When we consider language design based on what we can add but never subtract, we keep breaking changes to a minimum. This is why we’ve made almost no breaking changes throughout our multi-year history.
Conclusion
We explored Lean Software Development (LSD) and how it’s implemented effectively at JS++. In the next article, we will look at the full systems development life cycle (SDLC) at JS++.
References
1. Parr, T., & Fisher, K. (2011). LL(*): The Foundation of the ANTLR Parser Generator. Programming Language Design and Implementation (PLDI). doi: 10.1145/1993498.1993548
2. Kuhn, T. S. (2015). The Structure of Scientific Revolutions. Chicago, IL: The University of Chicago Press.
3. Crown Business. (2011). The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. New York.
4. Poppendieck, M., & Poppendieck, T. (2003). Lean Software Development: An Agile Toolkit. Boston: Addison Wesley.
6. The End Of The Line For GM-Toyota Joint Venture. (2010, March 26). Retrieved from http://ww.npr.org/templates/transcript/transcript.php?storyId=125229157.